Week 01
Overview
- What is the CUDA programming model?
- Hierarchy of thread groups
- Kernels and other language extensions
Resources
This material heavily borrows from the following sources:
Introduction
1. CUDA®: A General-Purpose Parallel Computing Platform and Programming Model
In November 2006, NVIDIA® introduced CUDA® , which originally stood for “Compute Unified Device Architecture”, a general purpose parallel computing platform and programming model that leverages the parallel compute engine in NVIDIA GPUs to solve many complex computational problems in a more efficient way than on a CPU.
CUDA comes with a software environment that allows developers to use C++ as a high-level programming language. Other languages, application programming interfaces, or directives-based approaches are supported, such as FORTRAN, DirectCompute, OpenACC.

2. A Scalable Programming Model
At the core of the CUDA parallel programming model there are three key abstractions:
- a hierarchy of thread groups
- shared memories
- barrier synchronization
They are exposed to the programmer as a minimal set of language extensions.
These abstractions provide fine-grained data parallelism and thread parallelism, nested within coarse-grained data parallelism and task parallelism.
Further reading and material
Optional reading and exercise on this topic at abstractions: granularity.
Programming model
3. Kernels
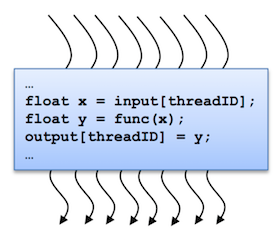
CUDA C++ extends C++ by allowing the programmer to define C++ functions, called kernels, that, when called, are executed N times in parallel by N different CUDA threads, as opposed to only once like regular C++ functions.
A kernel is defined using the __global__ declaration specifier and the number of CUDA threads that execute that kernel for a given kernel call is specified using a new <<<...>>> execution configuration syntax.
Each thread that executes the kernel is given a unique thread ID that is accessible within the kernel through built-in variables.
Kernel and execution configuration example
// Kernel definition
__global__ void VecAdd(float* A, float* B, float* C)
{
int i = threadIdx.x;
C[i] = A[i] + B[i];
}
int main()
{
...
// Kernel invocation with N threads
VecAdd<<<1, N>>>(A, B, C);
...
}
01. Question: raw to digi conversion kernel
- Find the kernel that converts raw data to digis.
- Where is it launched?
- What is the execution configuration?
- How do we access individual threads in the kernel?
4. Thread hierarchy
A kernel is executed in parallel by an array of threads:
- All threads run the same code.
- Each thread has an ID that it uses to compute memory addresses and make control decisions.
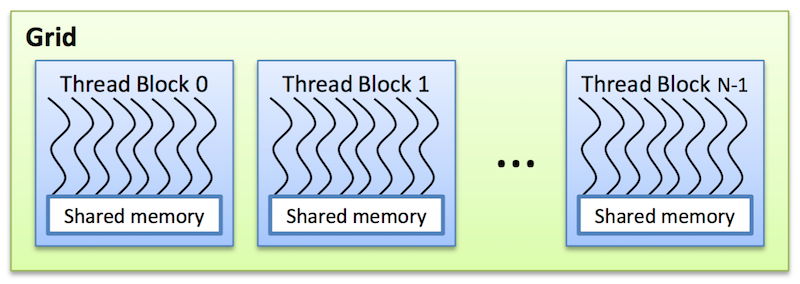
Threads are arranged as a grid of thread blocks:
- Different kernels can have different grid/block configuration
- Threads from the same block have access to a shared memory and their execution can be synchronized
Thread blocks are required to execute independently: It must be possible to execute them in any order, in parallel or in series.
This independence requirement allows thread blocks to be scheduled in any order across any number of cores, enabling programmers to write code that scales with the number of cores.
Threads within a block can cooperate by sharing data through some shared memory and by synchronizing their execution to coordinate memory accesses.
The grid of blocks and the thread blocks can be 1, 2, or 3-dimensional.
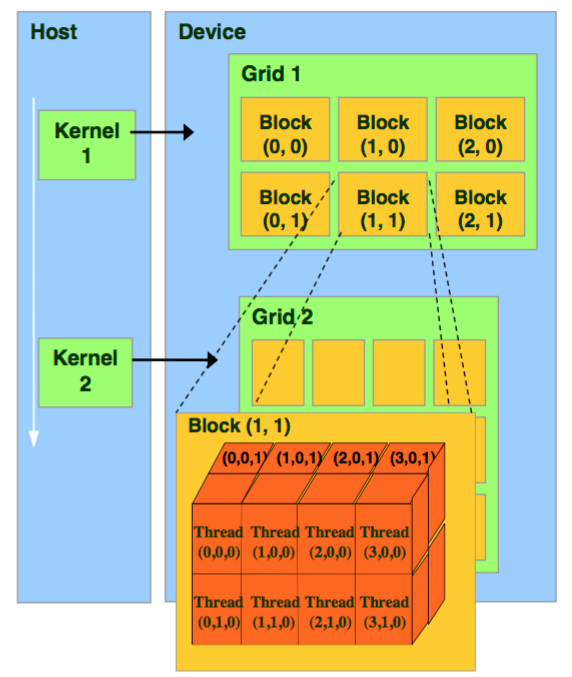
The CUDA architecture is built around a scalable array of multithreaded Streaming Multiprocessors (SMs) as shown below.
Each SM has a set of execution units, a set of registers and a chunk of shared memory.

5. Language extensions
From CUDA Toolkit Documentation: Language Extensions:
__global__
The global execution space specifier declares a function as being a kernel. Such a function is:
- Executed on the device,
- Callable from the host,
- Callable from the device for devices of compute capability 3.2 or higher (see CUDA Dynamic Parallelism for more details). A global function must have void return type, and cannot be a member of a class.
Any call to a global function must specify its execution configuration as described in Execution.
A call to a global function is asynchronous, meaning it returns before the device has completed its execution.
__device__
The device execution space specifier declares a function that is:
- Executed on the device,
- Callable from the device only.
The global and device execution space specifiers cannot be used together.
__host__
The host execution space specifier declares a function that is:
- Executed on the host,
- Callable from the host only.
It is equivalent to declare a function with only the host execution space specifier or to declare it without any of the host, device, or global execution space specifier; in either case the function is compiled for the host only.
The global and host execution space specifiers cannot be used together.
The device and host execution space specifiers can be used together however, in which case the function is compiled for both the host and the device.
02. Question: host and device functions
-
Give an example of
global,deviceandhost-devicefunctions inCMSSW. -
Can you find an example where
hostanddevicecode diverge? How is this achieved?
03. Exercise: Write a kernel in which
-
if we're running on the
deviceeach thread prints whichblockandthreadit is associated with, for exampleblock 1 thread 3 -
if we're running on the
hosteach thread just printshost.
6. Execution Configuration
From CUDA Toolkit Documentation: Execution Configuration
Any call to a global function must specify the execution configuration for that call. The execution configuration defines the dimension of the grid and blocks that will be used to execute the function on the device, as well as the associated stream (see CUDA Runtime for a description of streams).
The execution configuration is specified by inserting an expression of the form <<< Dg, Db, Ns, S >>> between the function name and the parenthesized argument list, where:
-
Dgis of type dim3 (see dim3) and specifies the dimension and size of the grid, such thatDg.x * Dg.y * Dg.zequals the number of blocks being launched; -
Dbis of type dim3 (see dim3) and specifies the dimension and size of each block, such thatDb.x * Db.y * Db.zequals the number of threads per block; -
Nsis of typesize_tand specifies the number of bytes in shared memory that is dynamically allocated per block for this call in addition to the statically allocated memory; this dynamically allocated memory is used by any of the variables declared as an external array as mentioned in shared; Ns is an optional argument which defaults to 0; -
Sis of typecudaStream_tand specifies the associated stream; S is an optional argument which defaults to 0.
Abstractions: Granularity
Granularity
If is the computation time and
denotes the communication time, then the Granularity G of a task can be calculated as
Granularity is usually measured in terms of the number of instructions executed in a particular task.
Fine-grained parallelism
Fine-grained parallelism means individual tasks are relatively small in terms of code size and execution time. The data is transferred among processors frequently in amounts of one or a few memory words.
Coarse-grained parallelism
Coarse-grained is the opposite in the sense that data is communicated infrequently, after larger amounts of computation.
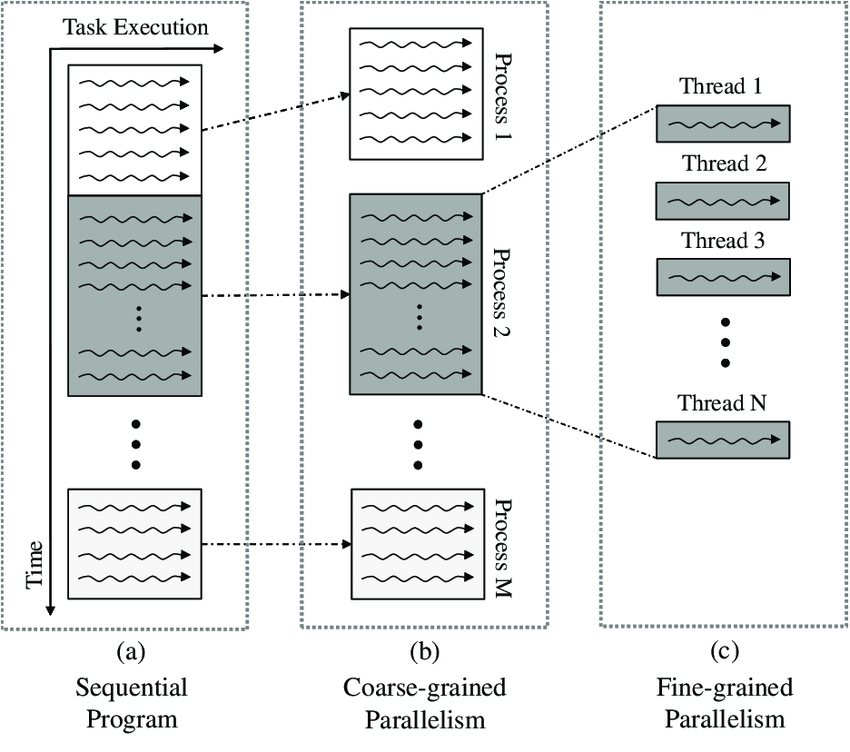
The CUDA abstractions provide fine-grained data parallelism and thread parallelism, nested within coarse-grained data parallelism and task parallelism. They guide the programmer to partition the problem into coarse sub-problems that can be solved independently in parallel by blocks of threads, and each sub-problem into finer pieces that can be solved cooperatively in parallel by all threads within the block.
This decomposition preserves language expressivity by allowing threads to cooperate when solving each sub-problem, and at the same time enables automatic scalability.
Indeed, each block of threads can be scheduled on any of the available multiprocessors within a GPU, in any order, concurrently or sequentially, so that a compiled CUDA program can execute on any number of multiprocessors.

The following exercise requires knowledge about barrier synchronization and shared memory.
Follow-up on __syncthreads() and shared memory.
04. Exercise: Fine-grained vs coarse-grained parallelism
- Give examples in the
MatMulKernelkernel of coarse-grained and fine-grained data parallelism (as defined in CUDA abstraction model) as well as sequential execution.